Tech Corner
Training with HRDAG: Rules for Organizing Data and More
I had the pleasure of working with Patrick Ball at the HRDAG office in San Francisco for a week during summer 2016. I knew Patrick from two workshops he previously hosted at the University of Washington’s Centre for Human Rights (UWCHR). The workshops were indispensable to us at UWCHR as we worked to publish a number of datasets on human rights violations during the El Salvador Civil War. The training was all the more helpful because the HRDAG team was so familiar with the data. As part of an impressive career which took him from Ethiopia and Kosovo to Haiti and El ...

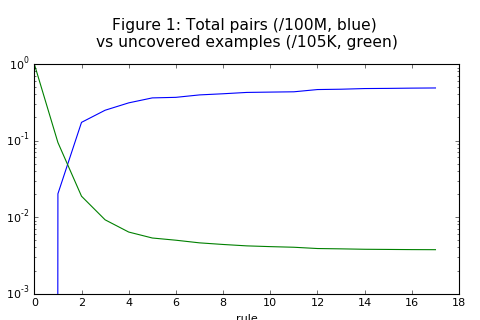
Using MSE to Estimate Unobserved Events
At HRDAG, we worry about what we don't know. Specifically, we worry about how we can use statistical techniques to estimate homicides that are not observed by human rights groups. Based on what we've seen studying many conflicts over the last 25 years, what we don't know is often quite different from what we do know.
The technique we use most often to estimate what we don't know is called "multiple systems estimation." In this medium-technical post, I explain how to organize data and use three R packages to estimate unobserved events.
Click here for Computing ...
Clustering and Solving the Right Problem
In our database deduplication work, we’re trying to figure out which records refer to the same person, and which other records refer to different people.
We write software that looks at tens of millions of pairs of records. We calculate a model that assigns each pair of records a probability that the pair of records refers to the same person. This step is called pairwise classification.
However, there may be more than just one pair of records that refer to the same person. Sometimes three, four, or more reports of the same death are recorded.
So once we have all ...
The task is a quantum of workflow
This post describes how we organize our work over ten years, twenty analysts, dozens of countries, and hundreds of projects: we start with a task. A task is a single chunk of work, a quantum of workflow. Each task is self-contained and self-documenting; I'll talk about these ideas at length below. We try to keep each task as small as possible, which makes it easy to understand what the task is doing, and how to test whether the results are correct.
In the example I'll describe here, I'm going to describe work from our Syria database matching project, which ...
A geeky deep-dive: database deduplication to identify victims of human rights violations
In our work, we merge many databases to figure out how many people have been killed in violent conflict. Merging is a lot harder than you might think.
Many of the database records refer to the same people--the records are duplicated. We want to identify and link all the records that refer to the same victims so that each victim is counted only once, and so that we can use the structure of overlapping records to do multiple systems estimation.
Merging records that refer to the same person is called entity resolution, database deduplication, or record linkage. For ...