
Clustering and Solving the Right Problem
 In our database deduplication work, we’re trying to figure out which records refer to the same person, and which other records refer to different people.
In our database deduplication work, we’re trying to figure out which records refer to the same person, and which other records refer to different people.
We write software that looks at tens of millions of pairs of records. We calculate a model that assigns each pair of records a probability that the pair of records refers to the same person. This step is called pairwise classification.
However, there may be more than just one pair of records that refer to the same person. Sometimes three, four, or more reports of the same death are recorded.
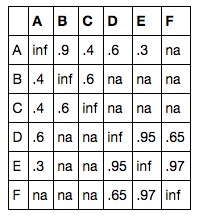
So once we have all the pairs classified, we need to decide which groups of records refer to the same person; together, the records that refer to a single person are called a cluster.
There may be 1, 2, or lots of records in a cluster. But heres’ a complication: if record A matches to record B, and record B matches record C, do all three match (A, B, C)? When you look at the cluster, you’ll find that maybe they do, and maybe they don’t.
This post explores how we think about clustering, and how we do it in software. Let us know what you think!