

Multiple Systems Estimation: The Matching Process
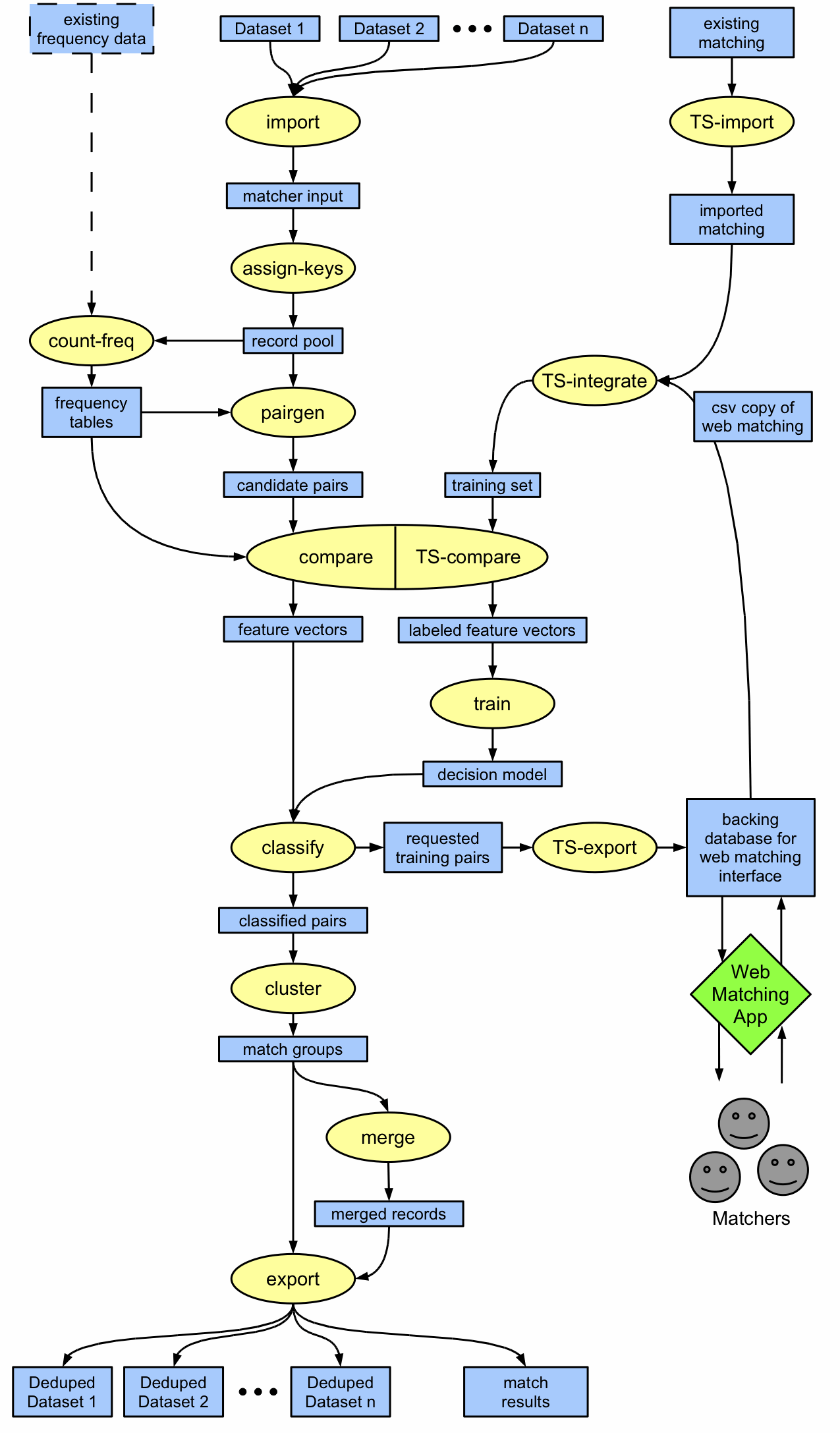
Matching process, implemented by HRDAG (Image: Jeff Klingner) (click to enlarge)
<<Previous post: Collection, Cleaning, and Canonicalization of Data
Q8. What do you mean by “overlap,” and why are overlaps important?
Q9. [In depth] Why is automated matching so important, and what process do you use to match records?
Q8. What do you mean by “overlap,” and why are overlaps important?
MSE estimates the total number of violations by comparing the size of the overlap(s) between lists of human rights violations to the sizes of the lists themselves. By “overlap,” we mean the set of incidents, such as deaths, that appear on more than one list of human rights violations. Accurately and efficiently identifying overlaps between lists is fundamental to the MSE process. However, determining how many items appear in more than one list can be a complicated process.
Consider the example of civilian killings during an armed conflict. If two organizations are keeping lists of civilian killings, these lists are convenience samples of the true “population” of killings, which is unknown. A sample is any subset of the true, unknown population of killings, and a convenience sample is any sample not gathered via a systematic, representative survey of the true, unknown population. Organizations’ lists are nearly always convenience samples, because they consist of killings that are reported in the media and/or killings reported directly to the organizations. It is important to remember that killings reported in a convenience sample might be very different, on average, from the full population of killings. For example, killings of poor people or those in rural areas may be much less likely to appear in a convenience sample than killings of rich urban-dwellers. So, we need a way to move from convenience samples to statistically valid inferences about the true population of killings. In a nutshell, that’s what MSE does—and the MSE process begins by identifying the overlaps between convenience samples. (More on convenience samples here.)
The overlap is the set of killings that appears on both of our hypothetical organizations’ lists. To achieve an accurate MSE result, we need an accurate measurement of the overlap between three or more lists (also known as systems) of human rights violations. To arrive at an accurate measurement of the overlap between lists, each case on each list should be identifiable, often by name, date of violation, location, age or other characteristics. This can be a very difficult task, since many victims of human rights violations may be recorded with incomplete or incorrect information. HRDAG has developed an automated matching program (described in Q9) that facilitates matching of large datasets. Without automated matching, it would not be feasible to determine the overlap between large datasets, and MSE could not proceed.
Q9. [In depth] Why is automated matching so important, and what process do you use to match records?
When we refer to “automation” in the context of matching, we mean using software and data analysis to assist human matchers in determining which records in a collection of several datasets represent the same events (usually the same human rights violations). We occasionally use the phrase “automated matching.” However, this process should not be thought of as an unsupervised, machine-only process. Because the HRDAG matching process relies on human coders to label some pairs of records as matches or non-matches, it is more properly thought of as an instance of semi-supervised machine learning.
Matching, however accomplished, is an indispensable element of any MSE estimate, because matching determines the size of the overlaps between datasets. Matching based on machine learning is important for several reasons, the most obvious of which is practical: human matching (“hand” or “by hand” matching) would overwhelm human capabilities.
Machine-learning processes are also preferable to human matching for theoretical reasons. First, automated matching is reproducible, meaning that it gives the same results for the same sets of parameters in every instance. Because human judgments vary over time, record type and a number of other factors, human matching is not reproducible. Second, because automated matching is both reproducible and fast, it is amenable to sensitivity analysis. It is important to ask questions about the sensitivity of any matching project to small rule changes. We might ask: “If we were slightly more lenient in judging potential matches with dates mismatched by several days, how would that affect our estimates?” But we would be unable to answer that question in a systematic way if we relied only on human matchers, both because human matchers’ “rules” for classification change over time and because human matchers take too long.
The HRDAG matching “pipeline” follows the same sequence of steps generally recognized in the broader literature on record linkage. Following canonicalization, it generates a restricted pool of “candidate pairs” by very quickly selecting pairs that are likeliest to match because they have particular characteristics (e.g., all those that occurred in the same state or department, all those that occurred in the same month, and so on). The matcher then performs more sophisticated similarity measurements on these candidate pairs. Based on these measurements (and on rules derived from any pairs already human-matched), the matcher selects an initial classification (match or not-match) with an associated confidence level (very sure to not at all sure). A small subset of records is returned to the human matcher, who classifies them, and the machine uses these re-classifications to update its rules.
The similarity-measurement => machine classification => human classification => rule-update process repeats until human matchers deem its accuracy sufficient. At this point, clusters must be formed from the pairs, using one of several methods. The simplest is transitive closure: if A matches B, and B matches C, then A matches C. A better method, and the one we use most frequently is hierarchical agglomerative clustering. Event records that cluster together are merged, and each merged record is marked with the datasets in which it originally appeared.
This diagram illustrates the full matching process as it is implemented by HRDAG, beginning with raw data (Dataset 1, Dataset 2…Dataset n) and ending with a single matched and merged dataset. (We’ll do a more in-depth post regarding this diagram in weeks to come.) This blogpost explains HRDAG’s record de-duplication in more detail.
Stay tuned for the next post, Stratification and Estimation >>
[Creative Commons BY-NC-SA, excluding image]