
The Statistics of Mortality Due to Conflict in Peru
Our short article “Reality and risk: A refutation of S. Rendón’s analysis of the Peruvian Truth and Reconciliation Commission’s conflict mortality study” was published in Research and Politics on Friday 22 March 2019 (you can read it here).
As the article’s title describes, we are responding to a criticism of the mortality estimates we created for the Peruvian Truth and Reconciliation Commission (TRC) in 2003. The 2003 analysis included estimates for the total number of killings by agents of the Peruvian state and by the insurgents of the Shining Path.
We believe Rendón’s analyses and results are wrong. As we wrote in our previous blogpost:
There are three bases for our rejection of Rendón’s methods and findings:
(i) his results are inconsistent with data that have been collected since the 2003 publication of the TRC report: he estimates lower numbers of people killed than the number of killings documented in interviews, which means his estimates cannot be correct;
(ii) the logic of his method is flawed: the lack of data forces him to cherry-pick unrepresentative locations and extrapolate to the rest, but cherry-picking biases his results. We note that this was the reason why the TRC dismissed this strategy in 2003;
and (iii) when we compare the two competing methods, using the appropriate tools from statistical theory, we find that Rendón’s method performs consistently more poorly than the original TRC approach.
Some of the evidence we used to support points (i) and (iii) comes from data published subsequent to the TRC’s work. This newer survey was conducted by the Peruvian Ministry for Women and Social Development (MIMDES) between 2003 and 2006, and published in 2006 (see some of this work here and here). A key point is that human rights data collection prior to the TRC largely ignored violence by the Shining Path. That lack of available data obliged us in 2003 to use an indirect estimation approach to estimating the Shining Path’s totals (a somewhat terse explanation of this indirect approach can be found in the second section of our new Technical Supplement, see here). The MIMDES survey contains lots of information about killings by the Shining Path. Thus, these new data greatly increase our ability to analyze patterns by perpetrator and locality.
Comparing imputed versus non-imputed values
One point on which we agree with Rendón is that records of victims without perpetrator attribution should not be considered a distinct category, but the labels should be treated as missing data. Most records have the perpetrator identified in the original research, but for those records with missing perpetrator information, the value can be set by imputation.
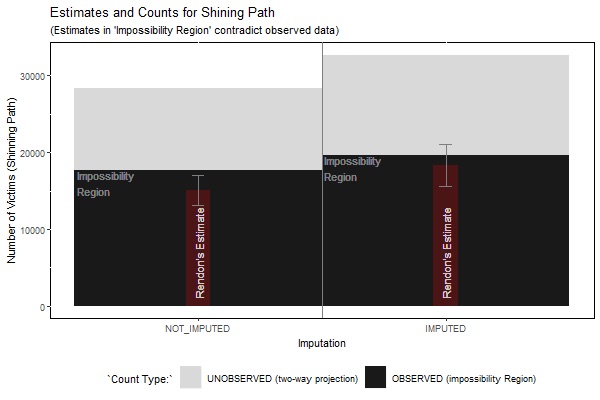
In our article, we showed that Rendón’s unimputed estimate of the total number of killings attributed to the Shining Path are lower than the also unimputed observed total number of deaths including those documented by MIMDES. This is our point (i) above. Some people have asked if this finding is also true using imputed totals. It is. The table below shows raw counts for Shining Path, after imputation of missing perpetrators (in this simple exercise we used the MICE technique via regression trees, and here we report the average [mean] imputed counts):
| in_2003 | in_MIMDES | n_SLU_imputed |
|---|---|---|
| Yes | Yes | 4340 |
| Yes | No | 6294 |
| No | Yes | 9002 |
| No | No | ?? |
| Total observed SLU | 19636 |
Rendón estimated a total of 18,341 for the overall Shining Path killings, which is much smaller than the observed count of 19,636. Keep in mind that the total estimate should include both the observed deaths and the unobserved deaths, so it must be larger than the observed total. Rendón’s estimate is considerably lower than the observed total, and thus cannot be correct.
The patterns of observation of deaths in the Peruvian conflict are extremely complex, with rich capture heterogeneity and list dependence (see here for more explanation of these challenges). Therefore one should not use the simple, two-list approach to estimate the number of unobserved deaths. However, as a starting point, we think it is valuable to observe that from the table above, the two-system estimate equals 6294 * 9002 / 4340 = 13,055. Note that this estimates the “No No” row indicated by “??” in the table above.
From this table, if the data collection in 2003 were independent of the data collection by MIMDES, and if all the victims had common (within dataset) probabilities of observation, we would expect that there would be approximately 13,055 additional, as-yet undocumented killings to be attributed to the Shining Path. This makes a total for killings attributed to the Shining Path in the vicinity 32,691.
To repeat, we don’t think the two list approach is a good way estimate of the likely total for the undocumented Shining Path killings. The data collection processes were not independent, and different victims had different probabilities of observation. Nonetheless, the scale of this simple estimate — 32,691 — is a strong indication that the total number of Shining Path killings is likely to be much greater than the observed total. This also means that Rendón’s total estimate of 18,341, which was already smaller than the observed count, is hopelessly too low. What’s more, this simple estimate is far outside his also (implausibly low) confidence interval of [15,637–21,045].
As we show in our article, this underestimation is no surprise. It is the logical consequence of Rendón’s flawed approach–see our point (ii) above.
Matching
The argument above depends on the accuracy of the three values in the table. Those in turn rely on whether we combined the datasets correctly, accurately identifying victims common to the different datasets. We address this point directly in our article (note that the counts referenced in the quote below refer to the unimputed counts, not the imputed counts described in the previous section; nonetheless the conclusions are identical).
A final note about “impossible regions.” We note that their accuracy ultimately rests in the quality of our matching of the MIMDES and 2003 datasets. Undermatching errors have the potential to alter our conclusions. However, we believe that this is unlikely. First, our matching within and among the datasets was aggressive, so much so that we identified 619 duplicates that the MIMDES team themselves did not detect. This makes our counts conservative. Second, Rendón’s SLU estimate is so low (\hat{N}=15,089), that for it to be physically possible it would be necessary that at least 6689 SLU records were common to the 2003 data and MIMDES. This is 72% of the 2003 records, and 63% more matches than the ones we detected (4091). We consider this unlikely.
Wrap-up
Following our previous blogpost, we want to reemphasize that we agree with Rendón that the TRC’s work deserves additional scientific attention. However, as we express in our article,
[…] noting improvements that could be made to TRC’s work does not by itself justify new results. To improve on the TRC’s work, alternatives should, at minimum, stand on their own: they have to be statistically sound, and should produce plausible results. In addition, if they are to contribute anything to the discussion, they should also have some advantage over the original other than merely appearing more obvious. Rendón’s work fails all three of these requirements. We agree with Rendón’s observation that the magnitude and distribution by perpetrator of killings during the Peruvian conflict are of great importance for Peruvian historical memory. We agree further that these questions merit considerable additional scientific attention. However, the flaws in Rendón’s (2019) article make it unsuitable to this discussion.
# # #