

Revisiting the analysis of event size bias in the Iraq Body Count
(This post is co-authored by Patrick Ball and Megan Price)
In a recent article in the SAIS Review of International Affairs, we wrote about “event size bias,” the problem that events of different sizes have different probabilities of being reported. In this case, the size of an event is defined by the number of reported victims. Our concern is that not all violent (in this case homicide) events are recorded, that is, some events will have zero sources. Our theory is that events with fewer victims will receive less coverage than events with more victims, and that a higher proportion of small events will have zero sources relative to large events.
The problem of event size bias is that analysis using biased data will overstate the relative importance of large events, and understate the frequency of small events. If large and small events differ in other ways (i.e., different perpetrators, different kinds of victims, different kinds of weapons), then analysis of those differences using the raw data will be inaccurate.
This post reconsiders the evidence and arguments we presented about event size bias in the Iraq Body Count (IBC), a collection of media and other sources about conflict-related killings in Iraq since 2003. After looking more closely, and with corrected data, we believe that the evidence more strongly supports our conclusions than we originally argued.
The analysis of IBC we published in the SAIS article (linked above) examines the relationship between event-size and the number of sources reporting each event. Our analysis assumed that the publicly available IBC data includes all the sources IBC has for each record.
This assumption is incorrect. In August 2014, Professor Michael Spagat (who works closely with IBC) emailed us noting that IBC publishes only some of the sources they track for each record. Furthermore, to our embarrassment, he reminded us that IBC had emailed us explaining the source limitation in October 2010! We regret the mistake, and we present corrected results below.
Professor Spagat also raised concerns about our citation of an article by Carpenter et al. in which they compare records from the US Army’s “significant acts” (SIGACTS) database (released to the public by Wikileaks, and published in summary form by the Guardian) to the events captured in IBC. Carpenter et al. find a strong association between the size of the events and the probability that the event is found in both SIGACTS and IBC’s sources (IBC included). In a series of emails, we discussed the concerns with Professor Spagat and with Carpenter et al.
Here is a very abbreviated summary of our conclusions:
1. There is event size bias in IBC. Everyone involved agrees, including IBC[1]. The debate is about how much bias there is, and how much the bias might affect analysis using the raw data.
2. IBC shared with us the complete source counts for the records with 3 or more sources for four months. By using data with the complete count of sources for each event, we find that the evidence in favor of event size bias is approximately ten times stronger than in our original analysis.
3. IBC and Carpenter et al. both matched data from SIGACTS to the other IBC sources, but they found quite different match rates. We believe that Carpenter et al. probably missed some of the matches in IBC. At the same time, we believe IBC overmatched. IBC linked individual incident reports from SIGACTS to “composite” records from other sources. We believe IBC is counting matches between an incident record and a composite record where there is insufficient information to establish (or reject) a link between the two records.
4. A substantial fraction of the records in IBC are not incidents, but instead are “composite” records aggregating information about several incidents. These records pose severe and probably insurmountable challenges to analysts who intend to use IBC to analyze quantitative patterns of killing over any of the dimensions recorded by IBC, including date, location, and type of weapon or event.
5. Most—but not all—of the records in IBC are anonymous, that is, they document an event (or several aggregated events) without listing the names of the victims. Our discussions with Professor Spagat and with Carpenter et al. highlighted the enormous challenges in matching reported deaths without the victims’ names. We are concerned that without sufficient information to match reliably, IBC may suffer from both undermatching (records that refer to the same deaths but are not linked) and substantial overmatching (multiple sources that refer to different deaths but are treated as one).
This post focuses primarily on correcting our previously published results. We’ll do deeper analysis in future publications, in particular, we’ll look into the implications of the different matching approaches and findings from IBC and Carpenter et al. and the challenge of what we call “composite” records in the IBC database.
As we emphasized in our original article, we think the Iraq Body Count is an indispensable source of information about violence since the US-led invasion. In particular, the link from specific dates, locations, and in some cases, incidents back to the original press sources is enormously useful.
However, we are skeptical about the use of IBC for quantitative analysis because it is clear that, as with all unadjusted, observational data, there are deep biases in the raw counts. What gets seen can be counted, but what isn’t seen, isn’t counted; and worse, what is infrequently reported is systematically different from what is always visible. Statistical analysis seeks to reduce the bias in raw data by making an estimate of the true value, and to calculate the probable error of the estimate. Without estimation, the analysis of raw data can be deeply misleading.
We are grateful to Professor Spagat for raising these points for our consideration; to Carpenter et al. for the discussion and clarifications; and to the IBC team for providing additional data. We should also be clear that the interpretations and conclusions described here are ours alone. Professor Spagat and members of the IBC team disagree with our conclusions.
Correcting our original analysis
Figure 2 in our original analysis showed the difference in the proportion of events at different sizes with different numbers of sources. As mentioned above, we found that smaller events tended to have fewer sources. The mean number of sources for events with one victim was about 1.8 sources, whereas for events with six or more victims, there were about 2.4 sources per event: the largest events had on average 30% more sources than the smallest events.
The corrected data makes the pattern far more pronounced. The events with one victim now have a mean of 2.8 sources per record, whereas events with 6-14 victims have 7.6 sources per record, and events with fifteen or more victims have an average of 12.5 sources per record. Figure A, below, shows the distribution of source counts for events of four different sizes. That is, the largest events have on average about 170%–350% more sources than the smallest events.
The corrected analysis here is based on our original download of the IBC dataset (7 Feb 2014), supplemented by four additional files IBC sent us in September 2014. These files include the number of sources for records with 3 or more sources in the months of February for the years 2007, 2008, 2009, and 2010; no other periods are included in Figure A. For the records in the supplementary data, we replaced the count of sources we had done originally with IBC’s count. From these records, we removed five records which are identified as data from morgues. These are not incidents, and so should not be considered in the same way.
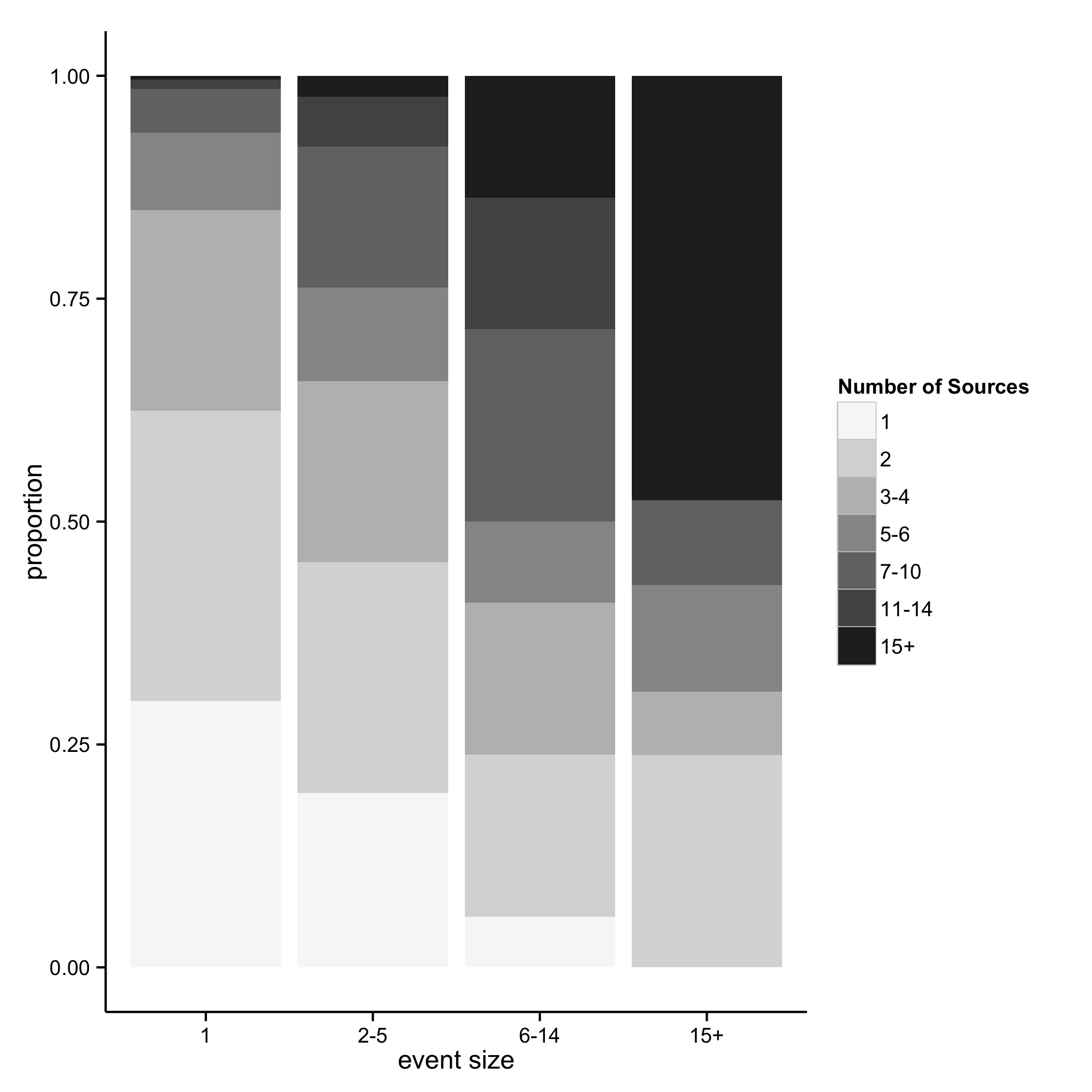
Figure A: distribution of source counts for events of four different sizes
Figure A shows, for example, that more than a quarter of events with only one victim have only one source. By contrast, nearly half of the events with fifteen or more victims have fifteen or more sources. Clearly, larger events get more sources.
Our fundamental question is: what kinds of incidents are not reported at all? In terms of this analysis, what incidents have zero sources? The theory behind analyzing source counts is that classes of incidents that have distributions of source counts skewed toward one will tend to have more unreported incidents (incidents with a source count of zero) than classes of incidents that have distributions of source counts centered farther from zero. Said differently, a positive correlation between event size and source count implies that events with fewer victims tend to have fewer sources, so more small events will tend to have zero sources; the correlation between event size and source count in these data is r = 0.5. This is the pattern observed in Figure A.
Discussion
In two analyses published on their website, IBC presented findings similar to what we present here, focusing on earlier periods. For example, see this from 2007 and this from 2008.
The question at issue is not whether IBC includes events of different sizes: clearly, they do. The question is whether the probability of reporting of an event varies with the event size. Large events of fifteen or more victims may have a reporting probability of one, that is, they are virtually certain to be reported in the media. Small events have smaller reporting probabilities.
We don’t know a way to calculate the reporting probabilities directly from source counts[2]. Nonetheless, the source count variability by event size is substantial, and should be worrisome to analysts.
Details of the differences between Carpenter et al. and IBC matching
As part of our analysis of event size bias, we cited an article by Carpenter et al.. With a logic similar to the argument we made above about source counts and event size, Carpenter et al. suggested that match rates that correlate with event size are evidence of event size bias. We referred specifically to their finding that “[e]vents that killed more people were far more likely to appear in both datasets, with 94.1% of events in which ≥20 people were killed being likely matches, as compared with 17.4% of … killings [that occurred one at a time].”
Professor Spagat raised a series of concerns about this article. Most importantly, he noted that in 2010, IBC sampled from SIGACTS and matched it to the existing IBC records, that is, they did something quite similar to Carpenter et al., but IBC found very different patterns.
IBC and Carpenter et al. agree that large events are generally found in both sources. Both studies find that approximately 95% of the largest events in SIGACTS are found in IBC’s other sources. The two reviews differ sharply on the rate at which the smallest events are found: IBC finds that 74% of the deaths in incidents with a single victim in SIGACTS’s “civilian” category are found in other IBC records, while Carpenter et al. find only 17% of single-victim events from SIGACTS in other IBC sources.
This difference — 17% vs 74% of the SIGACTS single-victim events being found in other IBC records — is the key analytic difference between the IBC and Carpenter et al. findings. Professor Spagat argued that Carpenter et al. undermatched, and that this explains the difference between their findings and IBC’s review. After discussion with Carpenter et al., we think it is possible that there was some undermatching in their analysis. We also think it is likely that IBC overmatched, and that IBC’s overmatching contributes substantially to the difference between the two studies.
The core of the difference between the two projects is how they approached matches to IBC’s aggregate, anonymous records, which we call “composites.” Composite records in the IBC are records which aggregate a group of victims who were killed in separate incidents but reported in a single count. IBC did not create these records. They come from news reports which take the form “Twelve bodies were found today in various locations in Baghdad…” that were then represented as a single record. This makes sense by understanding that IBC is a list of reports, not strictly as a list of incidents.
Here are the points that we think are relevant.
• Carpenter et al. did not have the full SIGACTS database: in their article, Carpenter et al. note that they used the data downloaded from the Guardian’s website. The full SIGACTS database includes more information than the Guardian’s summary, and the additional information could help with matching. We think that the most important information missing from the Guardian’s data is probably the reference in some SIGACTS records that the bodies were subsequently taken to a morgue. When the morgue published (approximately) monthly counts of bodies they recovered, IBC recorded the morgue information as a composite record with a large count. Given the imprecision of the morgue data, without the explicit reference from SIGACTS, it’s very unlikely that SIGACTS could be matched to it.
• There’s a broader matching problem with the morgue data, and with all composite records. It seems to us quite difficult to reliably match any incident-level record to any composite record (we discuss this in more detail in the following bullet). The interpretation we would suggest for Carpenter et al.’s analysis is that they are assessing SIGACTS matches to IBC incident records. That is, IBC’s match rates could be understood as the match rate from SIGACTS to IBC after removing all the composite records from IBC. Even with this constraint on the interpretation, Carpenter et al. may still be undermatching for other reasons, but it seems to us that narrowing the interpretation mitigates the fact that Carpenter el al. didn’t use the full SIGACTS records.
• Another problem with composite records is that they may have led IBC to overmatch the SIGACTS sample. In their explanation of how they matched the SIGACTS records to existing anonymous records, IBC presents an example in which they show that one composite record of 35 unnamed deaths could match 27 incident reports in the SIGACTS data (note that some of the SIGACTS incident reports have more than one victim). IBC says:
IBC entry k4435 simply records 35 bodies of persons found, typically killed execution style, across Baghdad over the course of 1 November, 2006. These few data points – the number, city, date and general cause of death – were the highest level of detail that existed in the public domain about these deaths until now. The Iraq War Logs also contain 35 bodies found on the same date in Baghdad, but spread across 27 logs specifying a wide range of details, including the precise neighbourhood and time of day where particular bodies were found and, in many cases, the demographics and identities of those killed.
It is possible that IBC’s single, composite record and the individual SIGACTS incidents matched to it truly refer to the same deaths, as this passage argues. It is also possible that the individual SIGACTS records refer to completely different deaths than the ones aggregated in the IBC composite record. And it’s possible that there is a complicated overlap, such that some of the SIGACTS records refer to deaths in the original composite, and other SIGACTS records refer to deaths not in the original composite. It is essentially impossible to confirm or reject any of these interpretations because there is so little detail in the original IBC composite.
We understand why IBC might adopt the aggressive matching approach they describe above: matching each SIGACTS incident report to an existing composite record is “conservative” in the sense that this approach would result in reporting the fewest deaths. Given IBC’s mission to report the toll of the Coalition invasion and occupation, this is a reasonable and justifiable decision. Nonetheless, this approach will tend to inflate the match rate they find, as well as causing other problems in quantitative analysis.
Based on our experience—we’ve matched literally millions of records in dozens of databases in Guatemala, El Salvador, Kosovo, Colombia, Syria, Timor-Leste, Liberia, and other places—we think it is very unlikely that the matches are perfect fits between the original composite and the individual SIGACTS records as described in the quoted passage. We think it is more likely that some SIGACTS records match some of the killings in the aggregate reports, and others do not. Based on the example IBC presented above, and the challenges inherent in matching anonymous composite records, we believe that it is likely that IBC overestimated the match rate between SIGACTS and the IBC data.
The problem of anonymous reports
Nearly all of the speculation described here about matching uncertainty is the consequence of using anonymous information, that is, reports that do not identify the victims by name. HRDAG’s work depends on accurate matching of records across lots of databases. Consequently, we do not use anonymous records[3]. A record of a death is identified by the name (usually a first and last name) of the victim, and the date and location of death. Having the given name means in most cultures and for most names that we also know the sex of the victim. We find that this is the minimum information necessary to disambiguate and to match records consistently and reliably.
There is an enormous amount of additional information that might be collected, including the age or date of birth of the victim; the victim’s ethnicity or religion; the manner of death or kind of weapon used; the individual or institutional perpetrator; the victim’s parent’s names; and a narrative of the incident, among many other possible fields. All of these can help to disambiguate and match records, but the absolute minimum necessary to consider a record is the name of the victim, and the date and location of death.
There are many, many corner cases that come from names: sometimes people from the same family have the same name, and are killed in the same incident, leading to an overmatch. In some societies, many people share a first or last name (or both)[4], making it difficult to distinguish among reports of their deaths. In some situations, people are known primarily by an alias or nom de guerre, and therefore reports of their deaths using different names may not be matchable (unless someone tells us both the name and the alias in the same report). In still other contexts, a person may get a local, indigenous name at birth, another (e.g., French) name when he attends a Catholic school, and a third (e.g., Arabic) name when he joins the army or the government or converts to Islam; the name the victim is known by will depend on his relationship to the person reporting his death. These are a few of the many complexities we have encountered in our work.
These problems are usually contextually specific, and they tend to be limited to a narrow subset of records that might refer to the same death. In our work, we have found ways to work around these issues. Unfortunately, working with anonymous records removes the only victim-specific identifier which is consistently found in records of deaths.
Finally, we are sensitive to the problem of fabrication in death reports. Politically-motivated actors sometimes invent stories of atrocities they attribute to their opponents. In our experience, it is much easier to invent a story with an anonymous reference to many victims than it is to create a list of fake victims (with invented dates and locations of death). Lists of identified deaths invite scrutiny, and if people from the affected area do not recognize at least some of the names on the list, questions about the list’s validity are quickly raised. By contrast, a vague report of many unnamed victims may be sufficient to gain at least temporary media attention. We respect journalists’ efforts to verify stories, and we further respect IBC’s effort to remove false reports. Our note here is simply that it is much harder to identify potentially inaccurate records when the victims’ names are unknown.
Determining whether one fully-identified record matches another can sometimes be challenging, but in all but a few pairs of records, it can be done. However, without the names of the victims, we do not believe anonymous records can be integrated consistently or reliably.
Conclusion
In our original article, we wrote that “Iraq Body Count … collect[s] invaluable data, and they do so systematically, and with principled discipline.” We still believe that the data in the IBC database is extremely valuable as an index to reports of violence in Iraq.
The laudable facts that IBC collects information systematically, and that they make it available publicly, do not mean that IBC presents a statistically representative sample of violence in Iraq. As is shown by every assessment we’re aware of, including IBC’s, there is bias in IBC’s reporting such that events with fewer victims are less frequently reported than events with more victims. We suspect there are other dimensions of bias as well, such as reports in Baghdad vs reports outside of Baghdad. Small events are different from large events, and far more small events will be unreported than large events. The victim demographics are different, the weapons are different, the perpetrators are different, and the distribution of event size varies over time. Therefore, analyzing victim demographics (for example), weapon type, or number of victims over time or space—without controlling for bias by some data-adjustment process—is likely to create inaccurate, misleading results.
After a reconsideration of the evidence and argument from our source count and event size analysis, and in the different matching rates presented by IBC and Carpenter et al., we believe the conclusions in our original article are substantially strengthened.
We think this analysis is increasingly important. IBC is one (albeit one of the best) of many emerging media-based data sources about political violence. The issues we raise here are likely to be more severe for conflicts that are less intensively covered than the conflict in Iraq. We urge analysts to seek methods to adjust raw data for statistical biases before drawing conclusions.
[1] See this page, in particular, IBC’s comment that “We had good reasons to expect that there would be a strong relationship between sizes of events, measured by the number of deaths, and the rate at which these would match against the IBC data, with deaths in larger events matching more frequently than smaller ones.”
[2] Species richness models are tempting, but carry strong assumptions. See “A Poisson-compound Gamma model for species richness estimation.” Wang, J.-P. , Biometrika, 2010, 97(3): 727-740. We cited this article in footnote 20 of the original article, but we now think the assumption of independent observations may be too difficult to manage. In particular, for the species-observation counts to be a reliable basis to estimate unobserved species, the analysis assumes that each observation is statistically independent of the others. Media reports are not independent: if one journalist finds a story, other journalists will also tend to cover the same story. This is “positive dependence,” and the result is that it will tend to bias estimates downward. We would very much like to hear more about how the independence assumption might be relaxed.
[3] See Ball et al., specifically section 4.4 on anonymous records. Note that in that report, we try to perform a kind of “minimum time-space count by complete match” estimate similar to the conservative approach it seems to us that IBC is trying to do here. This approach was not used in our analysis because we could not reconcile the contradictory assumptions that need to be made for interpretation.
[4] Some examples we have encountered include “Pedro Brito,” which is a very common name for men in the Ixil region of Guatemala; “Mau Bere,” a common name in Timor-Leste; and “Mohammed” forms part of the given name for approximately one-quarter to one-third of Syrian men and boys.
[CC BY-NC-SA]