

Convenience Samples: What they are, and what they should (and should not) be used for
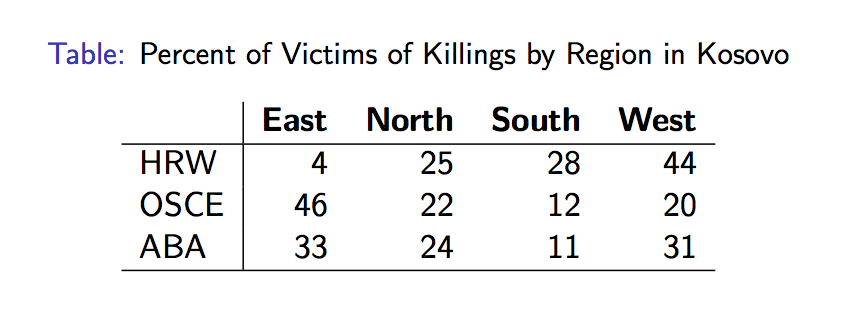
Comparison of three difference data sources collecting data on killings in Kosovo. Legend below.
As noted on our Core Concepts page, we spend a lot of time worrying about the ways data are used to make claims about human rights violations. This is because inaccurate statistics can damage the credibility of human rights claims. Analyses of records of human rights violations are used to guide policy decisions, determine resource allocation for interventions, and inform transitional justice mechanisms. It is vital that such analyses are accurate.
Unfortunately, all too often these decisions are based, inappropriately, on analyses of a single convenience sample.
Q1. What is a convenience sample?
Q2. What is a random sample?
Q3. Why does the relationship between a sample and a population matter?
Q4. Why is statistical inference not valid for a single convenience sample?
Q5. What are potentially negative outcomes of inappropriate use of convenience sample data?
Q6. What are examples of proper uses of convenience data?
Q7. What are proper data sources on which to base statistical inference?
Q8. Where has this been documented before and why am I reading it here?
Q1. What is a convenience sample?
A convenience sample, also called a non-probability or opportunity sample, among other names, is a sample drawn without any underlying probability-based selection method. Basically a convenience sample is any data that is neither a complete enumeration of all the possible data—a census—nor a careful, scientific sample. “Convenience samples” are rarely convenient to draw, but they are referred to this way to distinguish them from random samples (see Q2). Examples of convenience samples include testimonies presented to NGOs, UN Missions, or truth commissions, lists of airstrikes documented by observing them, text messages coming in from disaster-stricken areas, records collected by police forces during their daily duties, investigation records, and press reports, among many, many others. All of these are important, useful sources of data and many convenience samples are collected through very carefully designed data collection procedures (see, for example, Who Did What to Whom by Patrick Ball). However, the fundamental quality that defines them as convenience samples is the lack of an underlying probability-based selection method. In other words, convenience samples rely on data that is selected by those who provide it or those who observe it – information from individuals who chose to tell their stories to NGOs or reporters, incidents that happen to be witnessed by police, reports from individuals who own a cell phone and have the ability to send a text.
Absent a probability-based selection procedure, it is nearly impossible to describe quantitatively the relationship between a convenience sample and the underlying population of interest (see Q3). In other words, it is difficult to quantitatively describe the portions of the population that are included in a convenience sample. An important exception is the case where multiple samples have been collected, making it possible to model the selection process, even if this process was not explicitly planned and described prior to collecting the samples (see Multiple Systems Estimation).
A random sample, also called a probability sample, is one in which every member of the population has some chance (probability) of being selected into the sample, and this probability of selection can be calculated. This feature makes it possible to describe quantitatively the relationship between a random sample and the underlying population of interest (see Q3).
The essential point to remember is that random does not mean arbitrary. That is, choosing a random sample relies on an objective mechanism to select elements from the population. Random selection is usually done by a computer, but you can roll dice, choose playing cards, or choose every 10th house from a random starting point to get a random sample. The important idea is that no one can predict ahead of time who (or what) will be in a random sample.
There are many different methods for selecting a random sample (for example, simple random sampling, systematic sampling, stratified sampling, cluster sampling). Each method relies on the existence of a well-defined population of interest (for example, households in Timor-Leste) and a sampling frame – a list of all the potential sampling units (for example, census data on administrative units in Timor-Leste; see Appendix 5 of “The Profile of Human Rights Violations in Timor-Leste, 1974-1999″, a Report by the Benetech Human Rights Data Analysis Group to the Commission on Reception, Truth and Reconciliation for further details of this sampling example). Elements are then selected using a random procedure, meaning that subjective human preferences do not influence the selection of observations into the sample.
Q3. Why does the relationship between a sample and a population matter?
Most of the time when we collect data we are collecting a sample, a subset, from a population of interest. If our goal is to extrapolate from that sample to draw conclusions about the underlying population of interest, we must have knowledge about the relationship between the sample and the population. Have we collected data about 20% of the population or 80%? Does our sample include the same proportion of men and women as we expect in the population? Are there more young people in our sample than in the population? By knowing the relationship between our sample and the population, we can use the ways in which our sample does (or does not) represent the population to extend our conclusions from the sample to the population. This extension is technically referred to as statistical inference. For a single sample, statistical inference is only valid under a specific set of circumstances for a random sample.
Q4. Why is statistical inference not valid for a single convenience sample?
Since a convenience sample does not use a randomized process to select from a population, we cannot calculate the probability that any member of the population is included (or not) in the sample. Without this, we cannot quantify possible selection bias (also called reporting bias), which is the possibility that certain population members are more likely to be selected in the sample.
There are countless ways that a sample can be skewed towards a particular portion of the population. For example, areas with more violence may counter-intuitively produce fewer records of violence due to the danger of data collection in such regions. Certain religious or ethnic groups within a population may be more (or less) inclined to report to certain agencies or non-governmental organizations. As an organization’s resources change over time, it may have the capacity to collect more (or fewer) records, while the underlying population of interest may remain the same. As a result, patterns reflected in convenience data may be patterns of selection into the sample. Often, these patterns do not accurately describe events in the underlying population.
Because the factors that determine inclusion in a non-probability sample are so complex, and because these factors can change over time, it is impossible to measure how representative such a sample actually is.
Convenience samples can be great for descriptive observations about the observational units sampled, but they are inappropriate for analysis using statistical methods that assume randomness. Many key statistical operations, such as hypothesis testing and linear regression, rely on randomness for their validity, and thus these methods should not be used with a single convenience sample to build inferential conclusions. Applying inferential statistical analysis to a single non-random sample, though common, produces invalid conclusions.
Q5. What are potentially negative outcomes of inappropriate use of convenience sample data?
Our own research in human rights has taught us a) that convenience samples are often the only available source of data and b) drawing statistical inference from a single convenience sample frequently results in incorrect conclusions. We have discovered this by examining multiple convenience samples from projects in Colombia, El Salvador, Timor-Leste, Sierra Leone, Guatemala, and Kosovo. Drawing conclusions from a single sample in Sierra Leone would have led researchers to identify the wrong violation as the most frequently experienced by victims. Individual datasets in Colombia tell conflicting stories about which municipality has the highest incidence of violence. For detailed information from several of these examples and additional information about convenience samples and selection bias, see “Different Convenience Samples, Different Stories: The Case of Sierra Leone” by Anita Gohdes, “To Count the Uncounted: An Estimation of Lethal Violence in Casanare,” by Guberek et. al. (particularly section 3.4), and “It Doesn’t Add Up: Methodological and Policy Implications of Conflicting Casualty Data” by Krüger et al., a chapter in Counting Civilian Casualties.
Because such quantitative analyses help guide major policy decisions, it is imperative that researchers are careful in the generalizations and conclusions they make with the data available. Policy changes based on inappropriate extrapolations to a population not represented by convenience data could have harmful consequences.
Q6. What are examples of proper uses of convenience data?
Convenience samples provide vital contributions to individual case records, qualitative summaries, and documentation projects. When humanitarian assistance is needed during human rights or natural disasters, records of individual experiences of violence can help catalyze emergency responses. The details of individual testimonies can provide the necessary context in which to interpret quantitative research.
Q7. What are proper data sources on which to base statistical inference?
Statistical inference is appropriate in three cases:
- Data are from a random sample
- Data are a complete enumeration (e.g., a census)
- Multiple (possibly non-random) samples are analyzed using Multiple Systems Estimation (MSE)
Q8. Where has this been documented before and why am I reading it here?
The theory that underpins many statistical methods relies heavily on the assumption of randomness and the quantification of bias and inaccuracy. We have attempted to briefly introduce the basic definitions of convenience and random samples and the importance of the relationship between a sample and the underlying population from which it is drawn. The UC Davis Psychology department provides a longer introduction to sampling with examples and further references. Additionally, Chapter 1 of OpenIntro Statistics, a free introductory statistics text, is also an excellent resource on this topic.
As part of its mission, HRDAG is committed to building a community of human rights researchers using the best possible methodology under the ever-present challenges of quantitative work in this field. At HRDAG, we’re working to figure out how to use human rights data in quantitatively rigorous and defensible ways. If you have an idea about how statistical inference can contribute to human rights, we’d love to hear it!
Image: HRDAG.
legend: HRW = Human Rights Watch; OSCE = Organization for Security and Cooperation in Europe; ABA = American Bar Association
updated: 8 June 2013
[Creative Commons BY-NC-SA, excluding image]